不为谁而写的博客∎
Do it now - sometimes LATER becomes NEVER.
post @ 2019-09-08


post @ 2019-09-01
float,double类型的二进制表示
我们先来看看java中,double类型数据的二进制存储值,和展示的值。
1 | public class IEEE754 { |
输入如下:
post @ 2019-08-14
- 参数提示:
⌘P - 查看类的接口实现:
⌥⌘B - 查看继承关系(hierarchy):
⌃H - 返回上次查看的位置:
⌥⌘+左右方向键
post @ 2019-06-13
前言:关于Servlet
历史发展
https://blog.csdn.net/u010297957/article/details/51498018#commentBox
从CGI –> applet –> servlet(java) –> servlet1.1(jsp借鉴asp) –> servlet1.2(mvc思想) –> … –> Servlet3.1(稳定)
–> SpringMVC(本质也是Servlet)
Servlet规范
两个链接分别是Servlet官方文档和中文翻译版本。
狭义的看,Servlet就是一个interface,一个Java的接口,它有五个方法:
1 | public interface Servlet { |
13乎高赞回答,第一、二个回答醍醐灌顶了,爱了爱了。
功能
接受http请求,动态处理并返回结果给客户端。
Servlet与Tomcat
Tomcat是Servlet运行的容器。Servlet没有main方法,它受控于另一个Java应用,这个应用就成为容器(Container),而Tomcat就是Servlet的容器。而容器怎么处理用户的请求?我们来复现模拟这个过程:
- 客户端发起一个请求。
- 容器监听端口发现客户端的请求,创建
HttpServletRequest和HttpServletResponse两个对象 - 容器根据url判断把请求丢给哪个Servlet处理(根据映射规则),为这个请求创建一个线程,并把HttpServletRequest
和HttpServletResponse`丢给相应Servlet - 线程调用Servlet的service(),service()根据请求调用doGet()或者doPost()方法
- Service()处理完成,通过
HttpServletResponse把处理结果返回给Tomcat容器,Tomcat继续封装成http响应返回个客户端。
部署一个Servlet
安装Tomcat
本人在阿里云学生机安装Tomcat8,系统是ubuntu16.04,参考资料:
https://www.digitalocean.com/community/tutorials/how-to-install-apache-tomcat-8-on-ubuntu-16-04
编写和编译servlet
- 在
/opt/tomcat目录下创建一个myapp目录,接着在myapp下创建images(存放图片)、src(存放java源码)、WEB-INF,在WEB-INF下创建classes(存放字节码文件)和web.xml,目录树如下:
myapp/
├── images
│ └── test.JPG
├── src
│ └── TestingServlet.java
└── WEB-INF
├── classes
│ └── TestingServlet.class
└── web.xml
写一个helloworld版的servlet,使用vim写java你就会发现ide确实方便了开发。
1 | import javax.servlet.*; |
- 编译此文件,字节码文件输出到WEB-INFO/classes下:
javac -d ../WEB-INF/classes/ TestingServlet.java
配置web.xml
1 | <web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee" |
当你访问 host:8080/test时,tomcat容器会根据web.xml文件映射,把请求丢给名为Testing的servlet,而Testing会找到/WEB-INFO/classes下的TestingServlet字节码文件,处理完成返回客户端。
https://www.tutorialspoint.com/servlets/servlets-first-example.htm
http://www.informit.com/articles/article.aspx?p=26920&seqNum=4
post @ 2019-04-20
上一篇SpringBoot依赖注入中依赖注入的例子使用的是JavaConfig显示配置的方法。
回想一下,Config类,他显示地配置了很多的bean,每次都要自己配置不嫌麻烦?能不能省略显示配置的内容,让让Spring自动去发现类—–可以,这便是Spring自动装配。
Spring自动装配
ABC过于抽象,咱们这次换个生动的例子(《Spring实战》),我们为其取名为”音乐播放器和他的CD”。uml类图建模如下图所示: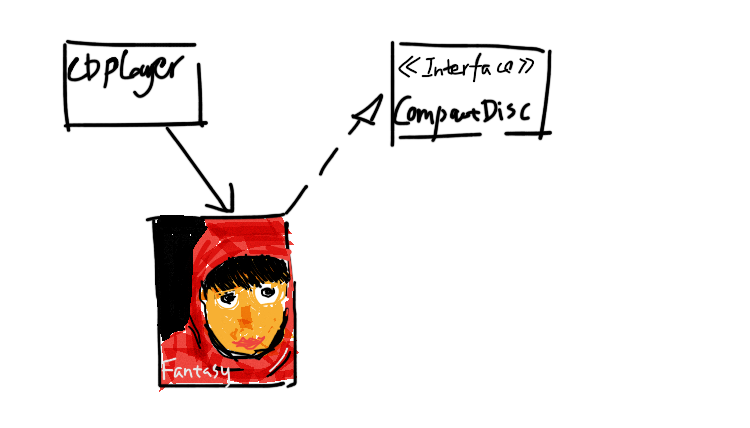
解释一下:CompactDisc有个play()方法,Fantasy(范特西)实现了CompactDisc接口,CDplayer使用Fantasy播放音乐。代码如下:
1 | public interface CompactDisc { |
1 | public class Fantasy implements CompactDisc{ |
1 | public class CDPlayer { |
类比一下上一篇的ABC,其实是一样的模子。按照上篇的思维,即显示配置Bean,接下来我们就需要写个Config类,然后在里面显示返回CDPlayer,Fantasy实例对象。你可以停下来想一想。周杰伦14张专辑都实现了CompactDisc接口,你都需要手动写,岂不是很麻烦,时间复杂度为O(n) = =。
好在Spring支持自动配置,解放了我们的双手!那我们该怎么改呢?CompactDisc接口不需要改动;Fantasy只需要在类之前使用@Component注解告诉Spring它是个组件,需要被扫描然后装入容器中,代码如下:
1 | // --------------> 改动 |
而CDPlayer也需要添加@Component注解。
1 | // --------------> 改动 |
@Autowired注解相当于告诉Spring,如果容器中存在CompactDisc的实例,那么在生成CDPlayerBean是,把CompactDisc实例依赖自动装入。最后我们需要一个CDPlayerConfig告诉Spring需要扫描哪些Component。
1 |
|
你会发现只要在组件上方添加@Component注解,并且使用@ComponentScan告诉Spring哪些组件需要被装入容器,你就能省略上篇冗杂在Config显示配置Bean。
SpringBoot简化操作
如果用过SpringBoot的同鞋可能发现,上述的两步走
- 在组件上方添加
@Component注解 - 使用
@ComponentScan告诉Spring哪些组件需要被装入容器
中的第二步是不需要开发人员做的,没错,SpringBoot简化了配置操作,但是不代表它没有做,它只是在幕后帮你完成了第二步。
post @ 2019-04-20
为什么需要DI
可能DI(依赖注入)这个词本身就不太好理解,首先我们先来看看官方的定义:
依赖注入会将所依赖的关系自动交给目标对象,而不是让对象自己去获取依赖。
比方说,你所要写的A类需要使用到B类的方法,
post @ 2019-04-14
环境
本地操作系统是Mac OS,使用的Navicat和Termial远程连接MySQL;远程是ALiyun服务器,ubuntu16.04,使用apt安装MySQL社区办作为数据库服务器。
1. 确保MySQL服务启动成功
首先要确保MySQL服务启动成功,可以使用systemctl status mysql或者service mysql status查看数据库运行状态。
2. 阿里云防火墙
确保服务器本地能够登录MySQL命令行之后,在浏览器打开阿里云管理控制台,添加防火墙规则,打开Mysqld默认监听的3306端口,如下图所示: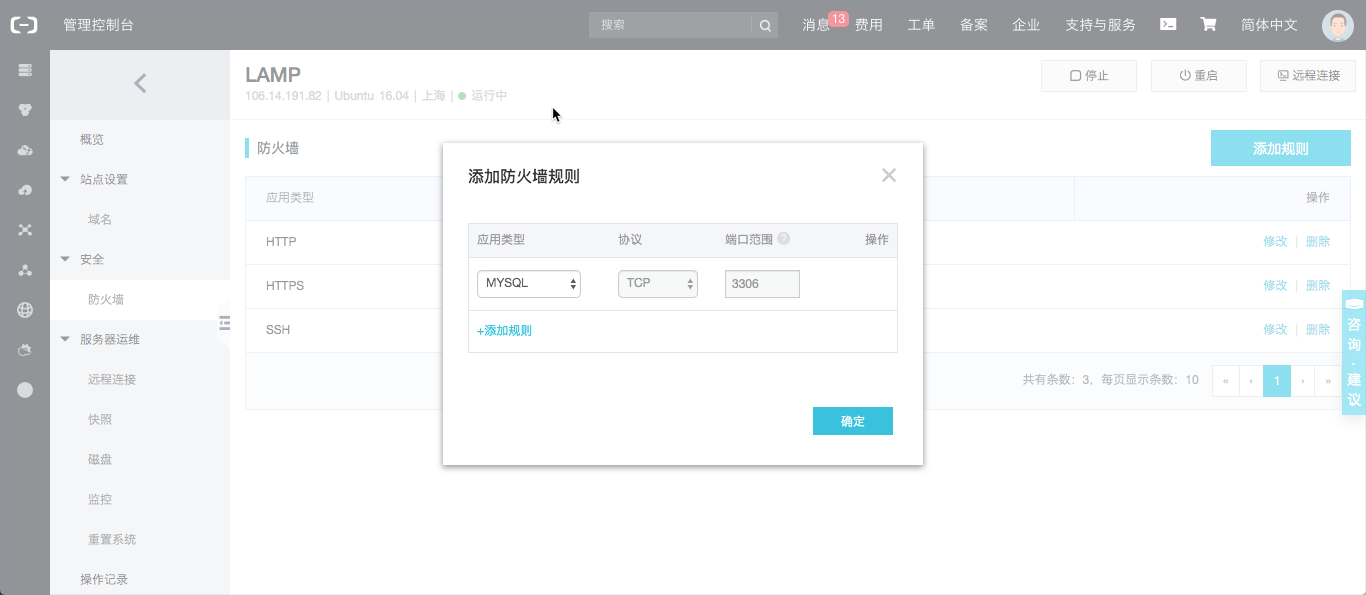
3. 修改MySQL 配置
MySQL默认只监听本地连接,所以我们必须手动打开。我的系统配置文件路径为/etc/mysql/mysql.conf.d/
mysqld.cnf,不同系统可能不同,不过,前缀路径/etc/mysql应该是一样的。可以使用find / -name mysqld.cnf寻找文件路径。在文件中,我们把bind-address = 127.0.0.1注释掉。
4. 授权
进入MySQL命令行,使用命令授权用户相关权限:1
grant all privileges on database_name.* to 'username'@'%' identified by 'password';
其中:
all是把所有权限给用户database_name.*是把database_name下的所有tables,当然你也可以把所有数据库连接权利给加上,只需要把database_name改成*即可。username,是连接的用户名,我这里设置成root%是指所有ip地址。你也可以指定特定ip地址。'password'是用户连接的密码,比方我设置成’123456’。然后用
flush privileges;命令刷新。
5. 重启MySQL
完成上述所有步骤之后,重启MySQL服务器。1
systemctl restart mysql
测试连接
- 本地终端
1 | mysql -h ip_of_your_remote_server -P 3306 -u root -p |
- Navicat
新建连接,连接属性设置如下图: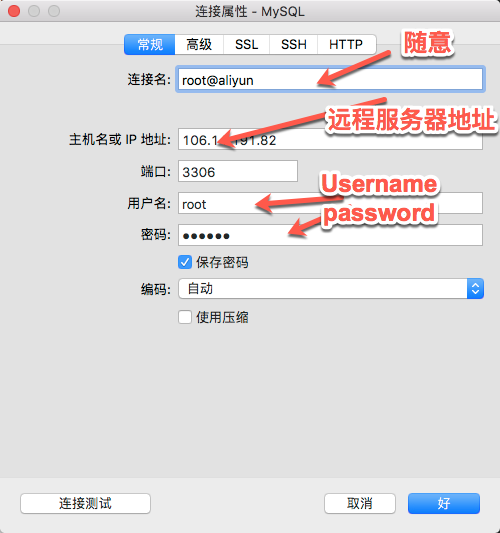
完
参考文章
https://www.jianshu.com/p/8fc90e518e2c
https://blog.csdn.net/enweitech/article/details/80677374
post @ 2019-04-14
- 索引的最左优先原则
- 聚集索引 vs 非聚集索引
post @ 2019-04-08
图的构造
我打算用图存各种人名,人际关系网络的初步实现。然后为了方便判断人名在遍历时是否已经访问过,我索性建立图的最小单位Node,类实现如下:1
2
3
4
5
6
7
8
9
10
11public class Node {
private String name; // 存储人名
private boolean marked; // 标记信息
public Node(String name){
this.name = name;
marked = false;
}
/******** getter and setter ********/
}
使用邻接表(Adjacent List)实现对图的表示,而邻接表用Map<Node,List<Node>>实现,map的键是图中的节点,键对应的值是与该节点邻接的所有节点,存放在List<Node>中。图的类属性和构造方法如下所示:
1 | public class G { |
上述代码能够通过构造函数构造没有节点的空图。所以在给他添上 addEdge(Node,Node)方法。
1 | public void addEdge(Node Node_1, Node Node_2){ |
例如,在调用addEdge(n1,n2)方法时,会在邻接表的键为n1对应的值中添加n2,同样也会在键为n2对应的值中添加n1。
为了使用BFS或者DFS,图必须还提供一个 返回某个特定节点的所有相邻节点,这个好实现:
1 | public List<Node> getAdj(Node n){ |
好了,图类就写好了。
BFS
BFS的思想就是利用队列存储节点的相邻节点。比方说我有个图如下图所示: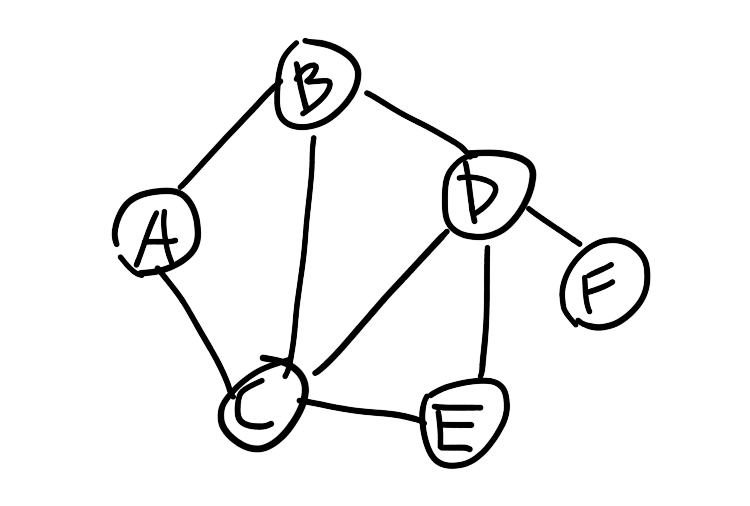
如果我们滴起始节点设为’A’,那么该思想就是意味着:把’A’放入队列,当队列不为空时,队列的队首元素(此时是A)出队列,然后将该元素(此时是A)的 相邻节点:’B’、’C’放入队列,重复上述步骤即可或得BFS结果。
1 | Queue<Node> queue = new LinkedList<>(); |
BFS除了有遍历图的功能,它也是图最短路径的基础。因为,BFS是一层一层遍历的,如图: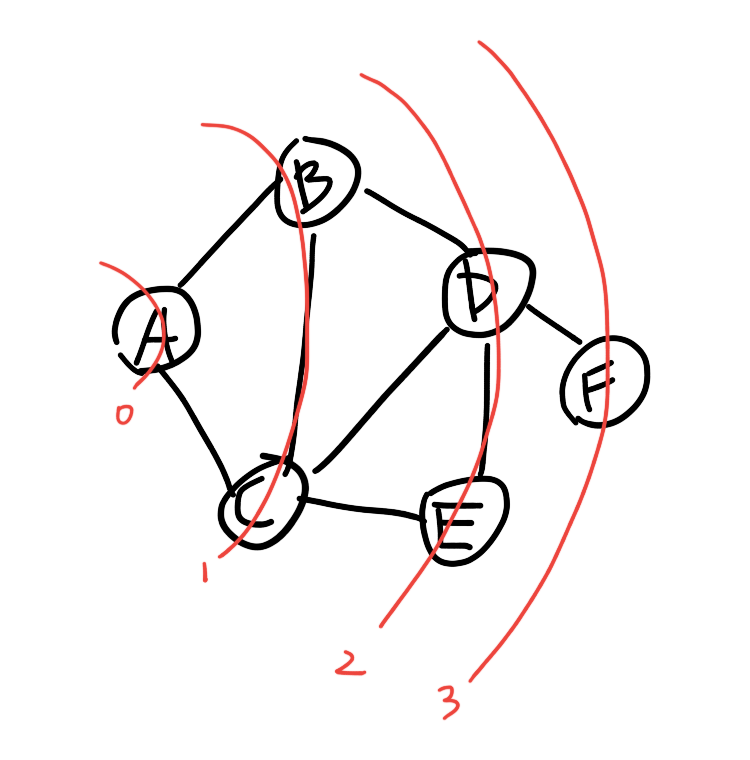
每一圈红色的曲线上的点到A的距离是相同的,就像水面的涟漪一样。但是,举个例子,想要知道A->D的路径经过了哪些节点,那么得在BFS遍历时额外存储的某个节点的上一个节点,如B->A,C->A,D->B,E->C,F->D,这些信息存储起来,那么A->D的路劲怎么求呢?,由于A->D的路劲等同于D->A,而D->A = D->B->A,从而解决了路径问题。
DFS
DFS的思想就是利用栈存储节点的相邻节点,可见,将队列换成栈,即可实现BFS到DFS的转换。
1 | Stack<Node> stack = new Stack<>(); |
post @ 2019-04-05
事务
‘事务’是具有‘原子性’操作的一组SQL语句,可以看做是一个工作单元。要么里面的SQL语句全部执行,要么里面的SQL语句全部不执行。
我们举个“银行转账”的经典例子: 账户A_account转账到账户B_account 1000CNY,那么转账系统需要至少三步操作:
- 检查A_account 的余额是否大于1000CNY
- 从A_account 的账户余额中减去 1000CNY
- 在 B_account 的账户中加上 1000CNY
将3步打包在一个事物里面,当3步骤中的任何一步出现了错误,就应该回滚所有已完成的操作。我们可以上述3步转换成SQL语句,首先我们,用start transation开启一个事物:1
2
3
4start transaction;
select balance from A_account where customer_id = 16058521;
update A_account set balance = balance - 1000 where customer_id = 16058521;
update B_account set balance = balance + 1000 where customer_id = 16058522;
事务的ACID
- A(Atomicity)原子性
- C(Consistency)一致性
- I(Isolation)隔离性
- D(Durability)持久性
原子性很好理解,要么执行,要么不执行。持久性也好理解,事物一旦提交,那么数据的改变是永久的。而一致性是啥意思呢?下面这句话是原话,各位客官自己理解吧= =
一种一致性状态转移到另一种一致性转态。
隔离性也就是今天的正题了,不同的隔离级别隔离强度不同,咱们下面细讲。
隔离级别
SQL标准定义了4种隔离级别,用来限定事务内外的哪些变化是可见的,哪些是不可见的。为了下面四个隔离级别实现的正常进行,我们先来看看怎么设置这四个级别:
- 查看隔离级别
1 | select @@tx_isolation; // 当前会话隔离级别 |
MySQL的InnoDB引擎默认隔离级别是REPEATABLE READ
1 | mysql> select @@tx_isolation; |
- 设置隔离级别
1 | set session transaction isolation level READ UNCOMMITTED; // 设置当前会话隔离级别为 未提交读 |
- 取消自动提交事务
1 | SHOW VARIABLES LIKE 'AUTOCOMMIT'; |
- 创建实验表,最后实验表结果如下所示:
1 | mysql> desc customer; |
我们会使用两个session链接模拟两个用户多数据库操作,分别为session A 和 session B。
READ UNCOMMITTED(未提交读)
首先我们在两个会话的isolation level均设置为READ UNCOMMITTED,或者你也可以在全局设置。
A:1
2
3
4
5
6
7
8
9
10
11
12
13mysql> start transaction;
mysql> select * from customer;
+----+-------------+
| id | name |
+----+-------------+
| 15 | Dasx |
| 19 | GapLockTest |
| 5 | Heikki |
| 20 | John |
| 21 | John |
+----+-------------+
5 rows in set (0.00 sec)
然后再B:
1 | mysql> start transaction; |
此时,B的事务尚未结束(使用commit提交事务),我们在A中再次查询:
1 | mysql> select * from customer; |
我们发现,在A中,已经能读取在B中未提交事务的变化。它会有个问题!当B的事务rollback了(John的名字没有修改),那么A读取的数据就是脏数据,也就是出现脏读(Dirty Read)
READ COMMITTED(已提交读)
在此级别,上述脏读问题就没有了,因为B只能读取到A的事务提交了之后数据。但是还是有个问题= =
首先我们将isolation level设置为READ COMMITTEDset session transaction isolation level READ COMMITTED;
A:
1 | mysql> start transaction; |
B:1
2
3mysql> start transaction;update customer set name='Dashi' where id=15;
mysql> commit;
此时B的事务已经提交,所以当A再去查询时,就会出现与第一次查询不同的结果(在我们看来感觉是合理的= =,B事务都提交之后A再查询当然会看到已经被B修改过的数据 = =),这就是不可重复读
A:1
2
3
4
5
6
7
8
9
10mysql> select * from customer; // Dasx变成了Dashi
+----+-------------+
| id | name |
+----+-------------+
| 15 | Dashi |
| 19 | GapLockTest |
| 5 | Heikki |
| 20 | John |
| 21 | Johnson |
+----+-------------+
这貌似很合乎逻辑啊。但它也会有问题,因为在A两次查询出现的结果是不同的。
REPEATABLE READ(可重复读)
此级别,也是MySQL默认的事务隔离级别,上述不可重复读问题就没有了,但理论上还是会有幻读(Phantom Read)的可能性。什么是幻读(Phantom Read),即: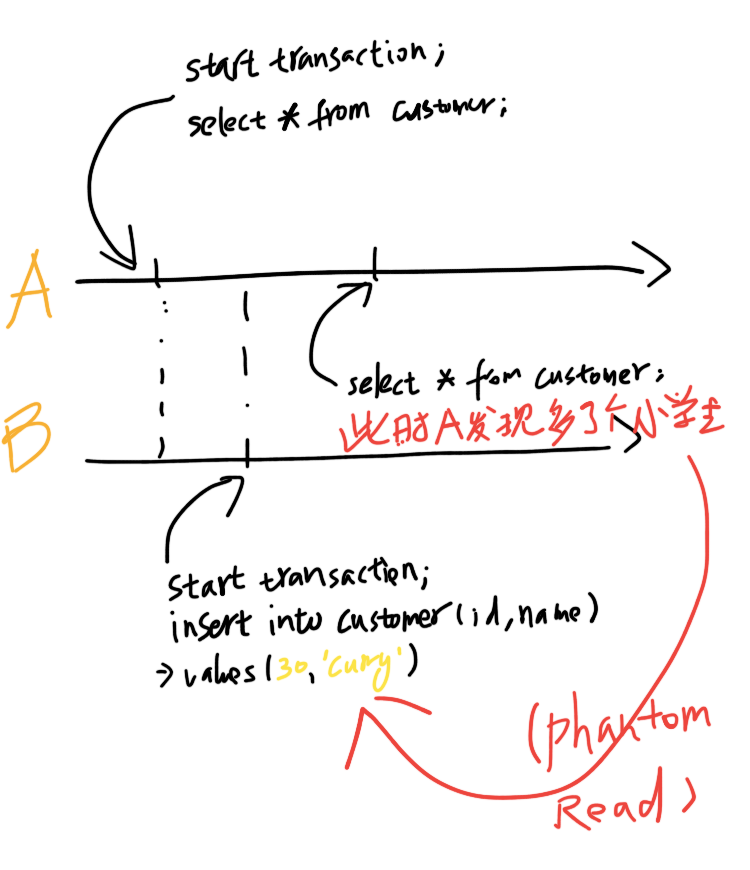
但是innodb的RR级别,使用GAP锁是解决了幻读的问题的(这个问题超出范围,下次再解释)。
SERIALIZATION(可串行化)
SERIALIZATION是最高的隔离级别,它通过强制事务排序,解决幻读问题。它会在每个读的数据上加排斥锁,让其他事务等待,但是这样做势必对性能造成影响。
同样,我们将A会话的事务隔离级别设置为serializable并开启事务。
A:1
2
3set session transaction isolation level serializable;
start transaction;
select * from customer;
B:
1 | mysql> begin;insert into customer(id,name) values(25,'Wangxb'); |
很明显,B事务出现了超时,只有当A在timeout时间内提交事务,B才会成功。