Java字符串
Java String类
字符串在java编程中应用广泛,有必要深入的了解一下。
创建字符串
java的String对象有2种创建方式:
- 字面值对象
- 构造方法创建对象。
第一种方式你可能没听说过,但你一定用过:
String s = "Hello World";,而用构造方法创建则是不太常用:String s = new String("Hello World");
这两种方式有何异同?我们有必要深究这两者之间的区别吗?两者有优劣之分吗?如果其一有绝对优势,劣势方是否有存在的必要?
我觉得这些问题都需要被解答。
对象问题
我们先做个Demo程序比较:1
2
3
4
5
6
7
8
9public class StringDemo {
public static void main(String[] args) {
String s2 = "Hello World";
String s1 = new String("Hello World"); // idea⚠️,不常用,会有性能问题.
System.out.println(s1 == s2); // false
System.out.println(s1.equals(s2)); // true
}
}
为什么s1==s2结果是false,而s1.equals(s2)结果是true呢?
其中涉及到了jvm(java virtual machine,java虚拟机)的构造原理。。根据JVM规范,JVM内存共分为虚拟机栈、堆、方法区、程序计数器、本地方法栈5个部分,感兴趣或者想进阶的还是找本JVM的书来看看,资历有限,就不展开了,如图: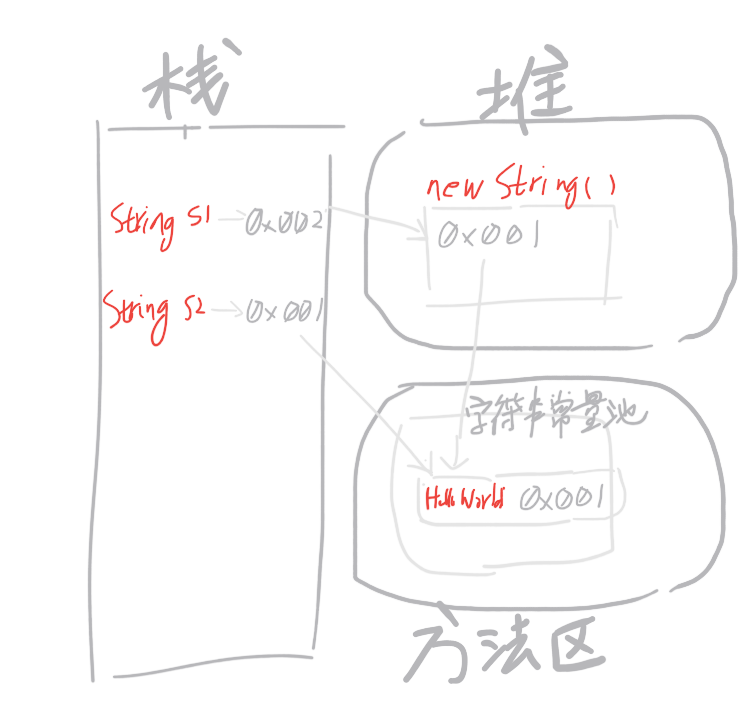
看了图应该很好理解,s2在常量池中开辟内存,地址为0x001,而s1在堆中开辟了新的空间0x002,由于发现在常量池中存在相同内容的”Hello World”,于是在其中存储了指向常量池的地址0x001,因为==符号比较的是操作数的地址,因此为false,而equals比较的是操作数的内容,因此为true。
此时我们便可以解释另一个问题:String s = "Hello World"和String s = new String("Hello World")两者分别产生了几个对象?在上述代码中(注意s1和s2的顺序),String s2 = "Hello World";产生了1个对象,String s1 = new String("Hello World");也产生了一个对象,而如果这两行代码位置互换,那么结果便不一样了(指的是对象个数):
1 | public class StringDemo { |
此时,String s1 = new String("Hello World");在”堆”中开辟了地址的同时,为了性能考虑,也会在”常量池”中开辟新地址,也就是产生了2个对象,而在运行String s2 = "Hello World";是,jvm扫描了常量池后发现有相同内容的常量,于是s2直接指向该地址,从而没有产生新对象。
String类不可变性质
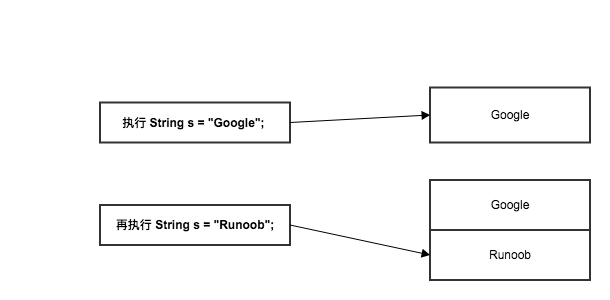
注意:String 类是不可改变的,所以你一旦创建了 String 对象,那它的值就无法改变了,所有的拼接,都会 产生新的对象,毫无疑问,如果需要对字符串做很多修改,性能会很成问题,那么应该选择使用 StringBuffer & StringBuilder 类,如下代码:
1 | String s = "Google"; |
输出结果为1
2Google
Runoob
从结果上看是改变了,但为什么门说String对象是不可变的呢?
原因在于实例中的 s 只是一个 String 对象的引用,并不是对象本身,当执行 s = “Runoob”; 创建了一个新的对象 “Runoob”,而原来的 “Google” 还存在于内存中。
那么问题是,为什么要保证String的”不可变性“,它有什么优点?明知道开发者大量使用String的拼接会造成性能问题?查阅相关资料后,有以下三个原因:
- 字符串池(String pool)的需求。之前已经说过,通过字面量发初始化一个Java字符串时,会将这个字符串保存在常量池中。如果定义了另外一个相同值的字符串变量,则直接指向之前初始化的那个对象。如果字符串是可变的,改变另一个字符串变量,就会使另一个字符串变量指向错误的值。
- 缓存字符串hashcode码的需要。字符串的hashcode是经常被使用的,字符串的不变性确保了hashcode的值一直是一样的,在需要hashcode时,就不需要每次都计算,这样会很高效。
- 出于安全性考虑。字符串经常作为网络连接、数据库连接等参数,不可变就可以保证连接的安全性。
字符串修改
你可以用符号”+”合并,或者String对象的concat()方法,但是在大量使用”+“或者concat()会大大增加编译的消耗,所以我们应该无脑使用StringBuilder或者StringBuffer。。。吗?
编译时优化
1 | /* |
为了提高效率和减少内存占用,Java编译器会在编译时做一些其力所能及的事情。上面的代码,从jdk1.5开始,由于在编译时即可以确定str1的值为”abcd”,所以编译时,直接将”abcd”字符串对象赋予str1,所以str1和str11引用的是常量池中的同一个对象。
隐式转换StringBuilder
1 | public class StringDemo2 { |
在这里,main函数的第三行s3会隐式调用StringBuilder来进行优化,也就是等价于1
2
3
4
5
6String s1 = "aaa";
String s2 = "bbb";
StringBuilder sb = new StringBuilder(s1);
sb.append(s2);
String s4 = "aaabbb";
System.out.println(s3 == s4); // false
好家伙,原来编译器对字符串的”+”操作有优化啊。那还折腾什么StringBuilder,直接上”+“,没毛病。。。吗?
循环拼接
1 | public class StringDemo2 { |
在这里,循环内的拼接每次都会new一个新的StringBuilder对象来隐式append(ss),所以循环多次,每次产生一个StringBuilder对象也会造成性能负担,我们应当在循环外显示的申明。1
2
3
4
5
6
7
8
9
10
11public class StringDemo3 {
public static void main(String[] args) {
StringBuilder s = new StringBuilder();
for (int i = 0; i < 10000; i++) {
int ss = new Random().nextInt();
s.append(ss);
}
System.out.println(s);
}
}
StringBuilder和StringBuffer
聊了那么多的String,也应当搞清楚了什么时候使用StringBuilder了,那么StringBuilder和StringBuffer又有什么区别呢?简单区分:
- StringBuffer 线程安全/StringBuilder 线程不安全
- StringBuilder 速度快
String的concat()和StringBuilder的append()差别
前面已经说了,String会产生一个新的String对象,而StringBuilder会在原来的字符数组上修改。那他们的区别到底是怎么产生的呢?我们可以分( )析()源码。首先,我们来看看StringBuilder的append:
首先映入眼帘的是:1
2
3
4
5
public StringBuilder append(String str) {
super.append(str);
return this;
}
很好,只是调用了父类的append,然后StringBuilder对象, 我们接着进入父类(AbstractStringBuilder
)的append()方法:
1 | public AbstractStringBuilder append(String str) { |
这里面ensureCapacityInternal()方法把value复制到一个空间大小为value.length+str.length的字符数组中,它源码如下:1
2
3
4
5
6
7private void ensureCapacityInternal(int minimumCapacity) {
// overflow-conscious code
if (minimumCapacity - value.length > 0) {
value = Arrays.copyOf(value,
newCapacity(minimumCapacity));
}
}
一层套一层,ensureCapacityInternal方法调用了Arrays.copyOf()方法,那我们顺着他继续看下去。1
2
3
4
5public static char[] copyOf(char[] original, int newLength) {
char[] copy = new char[newLength];
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
你没有看错,它有调用了System.arraycopy()方法,我们依旧义无反顾的走下去:1
2
3public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);
System类,一般我们很熟悉的方法莫过于标准输出:System.out.print()。而arraycopy被native修饰,表明它是一个原生函数,也就是最后用的是c++/c实现的。JNI(java native interface)允许java和其他语言写的代码进行交互。
而String的concat()方法源码如下:)
1 | public String concat(String str) { |
String常用用法(持续更新)
- 把数值型变量转成字符串类型
之前都是傻乎乎的先声明个字符串String s ="";,然后再使用字符串拼接的方式s += 555,获得555字符串。其实String类本身提供了相应的方法:String.valueOf()。
- 获取字符串的每个字符的ASCII码
char类型的字符是通过编码展示在你面前的,比如:1
int a = 'a'; // a = 97,字符'a'在默认编码(ascii)中对应数值是97
而你可以通过str.getBytes(编码方式):byte[]方法得到字符串每个字符的编码。1
2String str = "abcd";
byte[] byte = str.getBytes(StandardCharsets.US_ASCII); // UTF-8[97,98,99,100]
参考网址:
https://blog.csdn.net/xialei199023/article/details/63251366#commentBox
http://www.runoob.com/java/java-string.html
https://segmentfault.com/a/1190000009888357
https://blog.csdn.net/u012110719/article/details/45671557