MySQL事务隔离级别
事务
‘事务’是具有‘原子性’操作的一组SQL语句,可以看做是一个工作单元。要么里面的SQL语句全部执行,要么里面的SQL语句全部不执行。
我们举个“银行转账”的经典例子: 账户A_account转账到账户B_account 1000CNY,那么转账系统需要至少三步操作:
- 检查A_account 的余额是否大于1000CNY
- 从A_account 的账户余额中减去 1000CNY
- 在 B_account 的账户中加上 1000CNY
将3步打包在一个事物里面,当3步骤中的任何一步出现了错误,就应该回滚所有已完成的操作。我们可以上述3步转换成SQL语句,首先我们,用start transation开启一个事物:1
2
3
4start transaction;
select balance from A_account where customer_id = 16058521;
update A_account set balance = balance - 1000 where customer_id = 16058521;
update B_account set balance = balance + 1000 where customer_id = 16058522;
事务的ACID
- A(Atomicity)原子性
- C(Consistency)一致性
- I(Isolation)隔离性
- D(Durability)持久性
原子性很好理解,要么执行,要么不执行。持久性也好理解,事物一旦提交,那么数据的改变是永久的。而一致性是啥意思呢?下面这句话是原话,各位客官自己理解吧= =
一种一致性状态转移到另一种一致性转态。
隔离性也就是今天的正题了,不同的隔离级别隔离强度不同,咱们下面细讲。
隔离级别
SQL标准定义了4种隔离级别,用来限定事务内外的哪些变化是可见的,哪些是不可见的。为了下面四个隔离级别实现的正常进行,我们先来看看怎么设置这四个级别:
- 查看隔离级别
1 | select @@tx_isolation; // 当前会话隔离级别 |
MySQL的InnoDB引擎默认隔离级别是REPEATABLE READ
1 | mysql> select @@tx_isolation; |
- 设置隔离级别
1 | set session transaction isolation level READ UNCOMMITTED; // 设置当前会话隔离级别为 未提交读 |
- 取消自动提交事务
1 | SHOW VARIABLES LIKE 'AUTOCOMMIT'; |
- 创建实验表,最后实验表结果如下所示:
1 | mysql> desc customer; |
我们会使用两个session链接模拟两个用户多数据库操作,分别为session A 和 session B。
READ UNCOMMITTED(未提交读)
首先我们在两个会话的isolation level均设置为READ UNCOMMITTED,或者你也可以在全局设置。
A:1
2
3
4
5
6
7
8
9
10
11
12
13mysql> start transaction;
mysql> select * from customer;
+----+-------------+
| id | name |
+----+-------------+
| 15 | Dasx |
| 19 | GapLockTest |
| 5 | Heikki |
| 20 | John |
| 21 | John |
+----+-------------+
5 rows in set (0.00 sec)
然后再B:
1 | mysql> start transaction; |
此时,B的事务尚未结束(使用commit提交事务),我们在A中再次查询:
1 | mysql> select * from customer; |
我们发现,在A中,已经能读取在B中未提交事务的变化。它会有个问题!当B的事务rollback了(John的名字没有修改),那么A读取的数据就是脏数据,也就是出现脏读(Dirty Read)
READ COMMITTED(已提交读)
在此级别,上述脏读问题就没有了,因为B只能读取到A的事务提交了之后数据。但是还是有个问题= =
首先我们将isolation level设置为READ COMMITTEDset session transaction isolation level READ COMMITTED;
A:
1 | mysql> start transaction; |
B:1
2
3mysql> start transaction;update customer set name='Dashi' where id=15;
mysql> commit;
此时B的事务已经提交,所以当A再去查询时,就会出现与第一次查询不同的结果(在我们看来感觉是合理的= =,B事务都提交之后A再查询当然会看到已经被B修改过的数据 = =),这就是不可重复读
A:1
2
3
4
5
6
7
8
9
10mysql> select * from customer; // Dasx变成了Dashi
+----+-------------+
| id | name |
+----+-------------+
| 15 | Dashi |
| 19 | GapLockTest |
| 5 | Heikki |
| 20 | John |
| 21 | Johnson |
+----+-------------+
这貌似很合乎逻辑啊。但它也会有问题,因为在A两次查询出现的结果是不同的。
REPEATABLE READ(可重复读)
此级别,也是MySQL默认的事务隔离级别,上述不可重复读问题就没有了,但理论上还是会有幻读(Phantom Read)的可能性。什么是幻读(Phantom Read),即: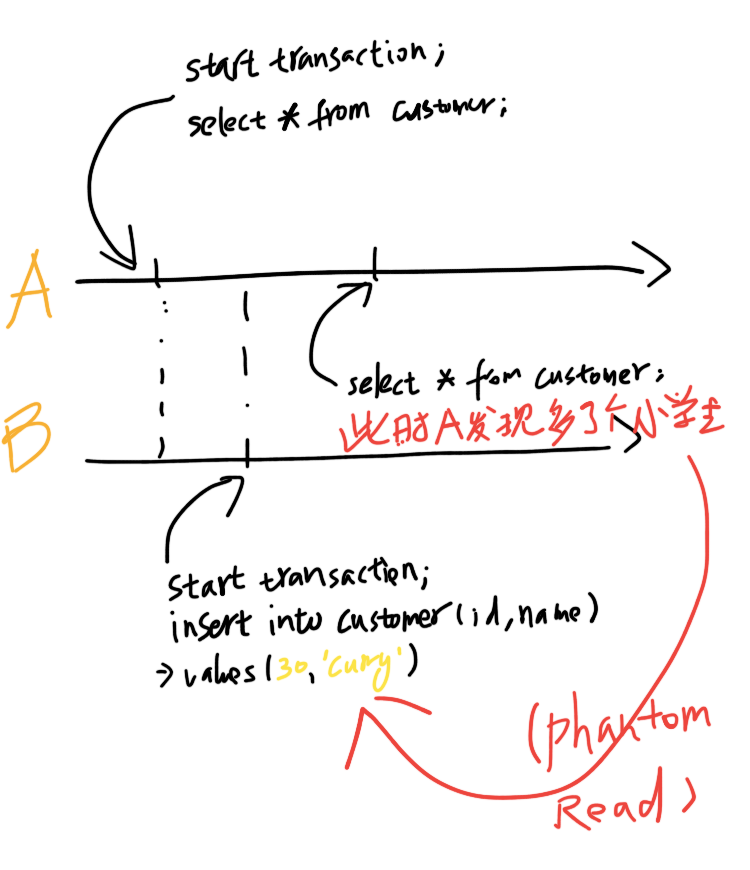
但是innodb的RR级别,使用GAP锁是解决了幻读的问题的(这个问题超出范围,下次再解释)。
SERIALIZATION(可串行化)
SERIALIZATION是最高的隔离级别,它通过强制事务排序,解决幻读问题。它会在每个读的数据上加排斥锁,让其他事务等待,但是这样做势必对性能造成影响。
同样,我们将A会话的事务隔离级别设置为serializable并开启事务。
A:1
2
3set session transaction isolation level serializable;
start transaction;
select * from customer;
B:
1 | mysql> begin;insert into customer(id,name) values(25,'Wangxb'); |
很明显,B事务出现了超时,只有当A在timeout时间内提交事务,B才会成功。