可视化决策树
这次使用到了一个重要的包:scikit-learn,它是用Python机器学习的重要模块。还没安装的同鞋直接pip安装即可。1
(python36) ➜ ~ pip install scikit-learn
二话不说,直接进入正题。咱们先导入如要使用的包。sklearn.tree是决策树类,sklearn.datasets是咱们使用的数据。1
2
3import sklearn.tree as tree
import sklearn.datasets as datasets
import numpy as np
咱们的用的数据是iris,是机器学习的经典数据,通过机器学习分类iris花的种类,具体可见https://en.wikipedia.org/wiki/Iris_flower_data_set。数据内建在datasets,我们直接加载。1
iris = datasets.load_iris()
为了测试数据呢,咱们选出几个数据用作测试。下标为0,50,100的数据正好是iris的三种花的第一个数据。1
test_idx = [0,50,100]
接下来,我们除去上面的三个数据,作为训练数据,这三个数据作为测试数据。监督学习都会有一个features,target,iris的数据也是同样,iris有两个成员变量,iris.data、iris.target,分别是iris的特征和分类结果。1
2
3train_data = np.delete(iris.data,test_idx)
train_target = np.delete(iris.target,test_idx)
test_data, test_target = iris.data[test_idx], iris.data[test_idx]
现在我们用构造一个决策树分类器。fit方法有两个变量:train_data,train_target,简而言之,通过训练数据’调教’决策树的分类参数。1
2clf = tree.DesicionTreeClassfifier()
clf.fit(train_data,train_target)
‘调教’完分类器后,我们便可以用分类器预测分类了。1
2
3predict = clf.predict(test_data)
print('predict: ',preditc)
predict: [0 1 2]
我们可以查看一下预测的正确率,因为一共只有三个测试数据,正确率完全098k,你也可以预测自己添加的数据。使用了skearn.metrics类,这个类可以很方便的帮助我们计算争取率。(metrics是‘公制的’意思)1
2import sklearn.metrics as metrics
print(metrics.accuracy_score(test_target,predict))
最后,把决策树分类器可视化。我们需要导入pydotplus包,而不仅如此,我们需要暗转graphviz的可视化软件,graphviz不是python的包。homwbrew安装即可。1
➜ ~ brew install graphviz
下面的代码原理就不深究了吧。又不是不能用。1
2
3
4
5
6
7
8import pydotplus
dot_data= tree.export_graphviz(clf,
out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True,rounded=True,impurity=False)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf('IrisTree.pdf')
生成的图片如下: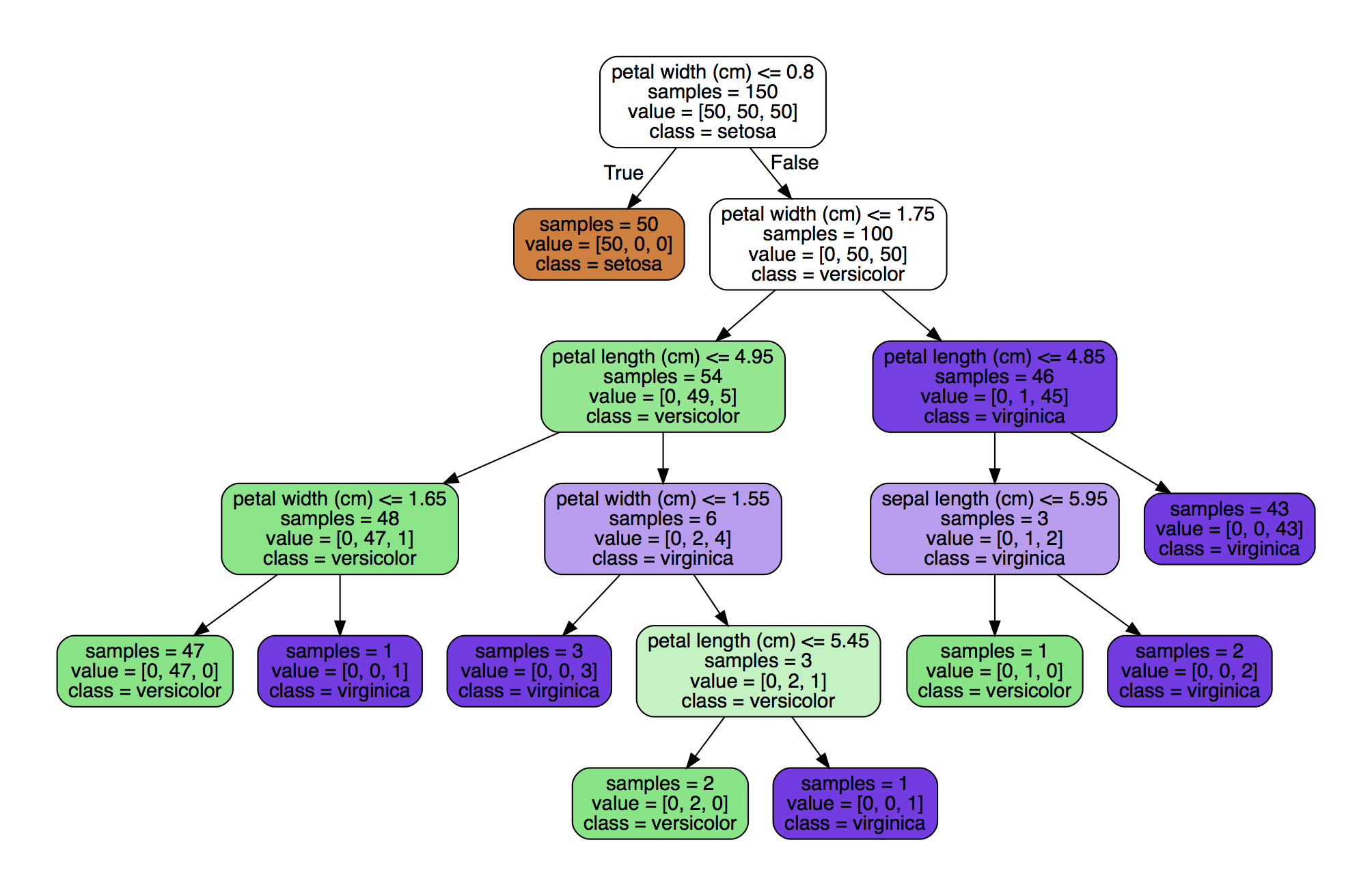
然后我们想着,这个clf模型挺好用的不是,如果下次还想继续使用这个模型,我们每次还得重新训练一遍?数据量小还能接受,花了几个小时训练的模型只能用一次就显得铺张浪费了,所以我们要把它保存起来。咱们使用到了sklearn.externals的joblib。也可以使用pickle实现,不过joblib对大数据的效率更高。1
2
3import sklearn.externals as ext
ext.joblib.dump(clf,'路径/iris_tree.pkl')#保存
clf2=ext.joblib.load('路径/iris_tree.pkl')#加载